Как всё устроено
.png)
Хранение данных: Cypress
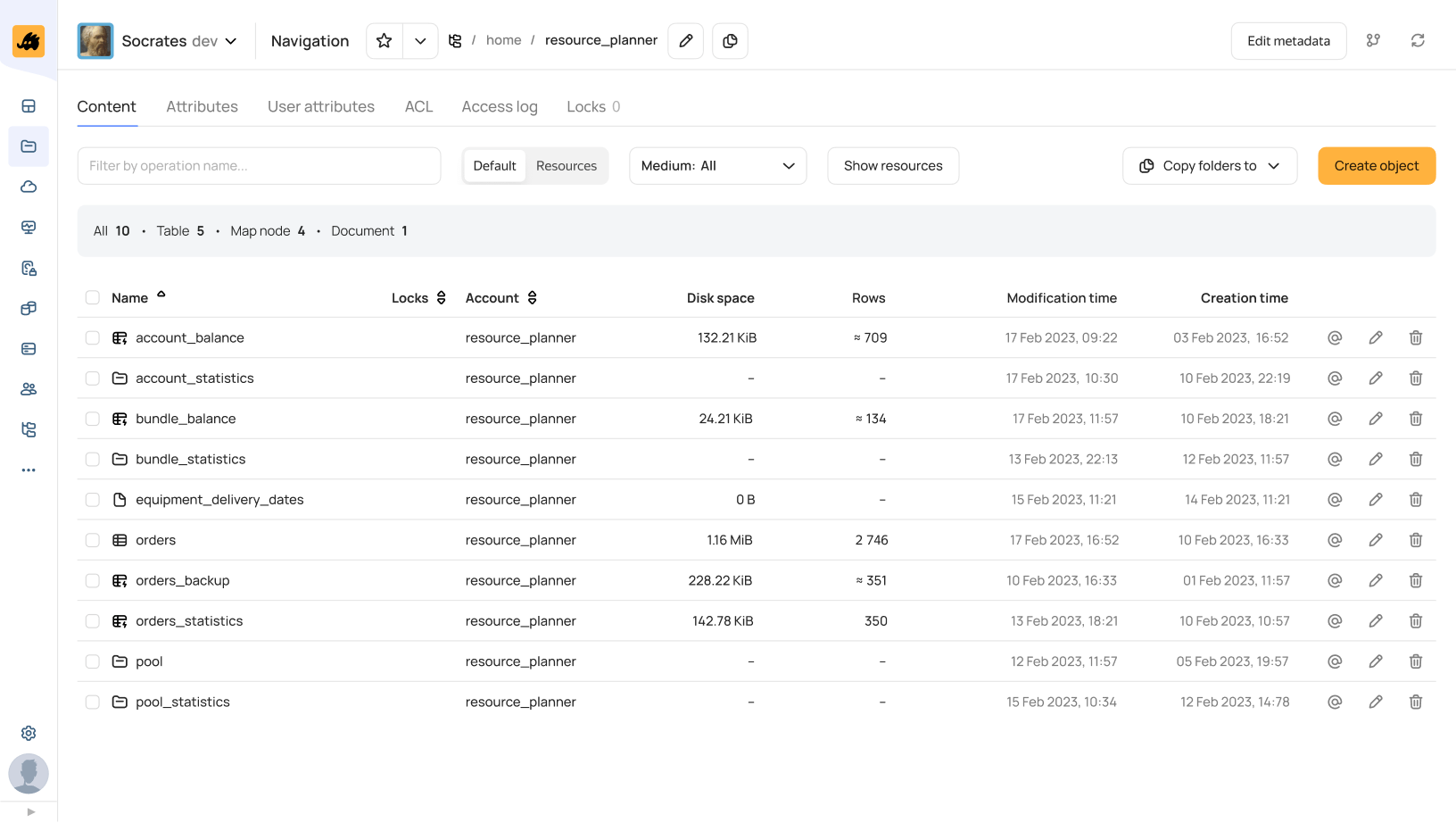
Динамические таблицы
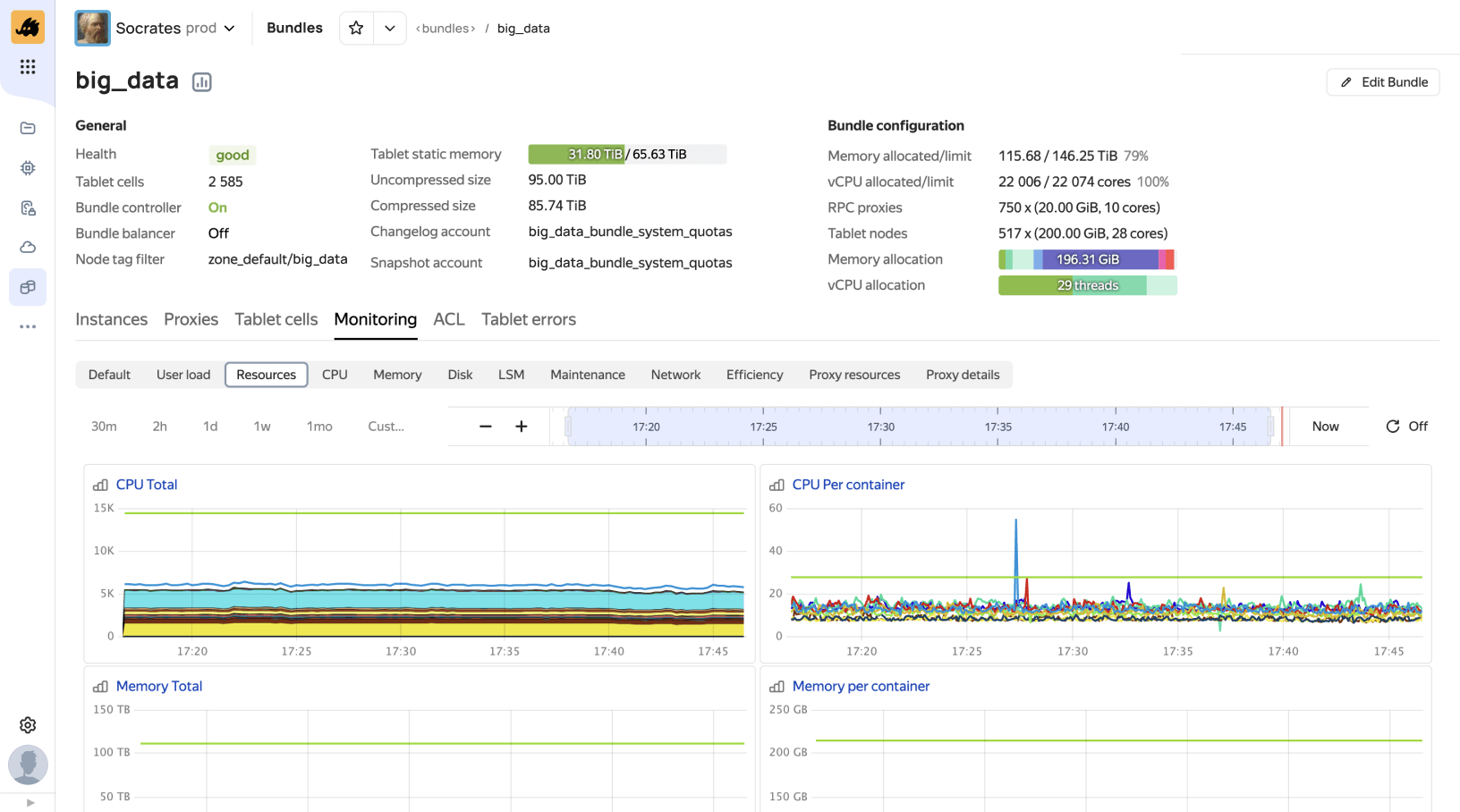
Очереди YTsaurus
Это распределённый, реплицированный журнал сообщений на базе динамических таблиц с поддержкой шардирования и межкластерной репликации. Они поддерживают чтение и запись по протоколу Apache Kafka.
Гибкое хранение на основе таблиц
Сообщения можно экспортировать в статическую таблицу для долгосрочного хранения, а после обработки возможно удалять по TTL.
Единое пространство транзакций
Благодаря единому пространству транзакций с динамическими таблицами возможна exactly-once обработка событий без сложных интеграций и сторонних инструментов.
Масштабируемость и отказоустойчивость
Использование шардирования и распределённого хранения позволяет масштабировать систему горизонтально без единой точки отказа.
Обработка данных: Scheduler
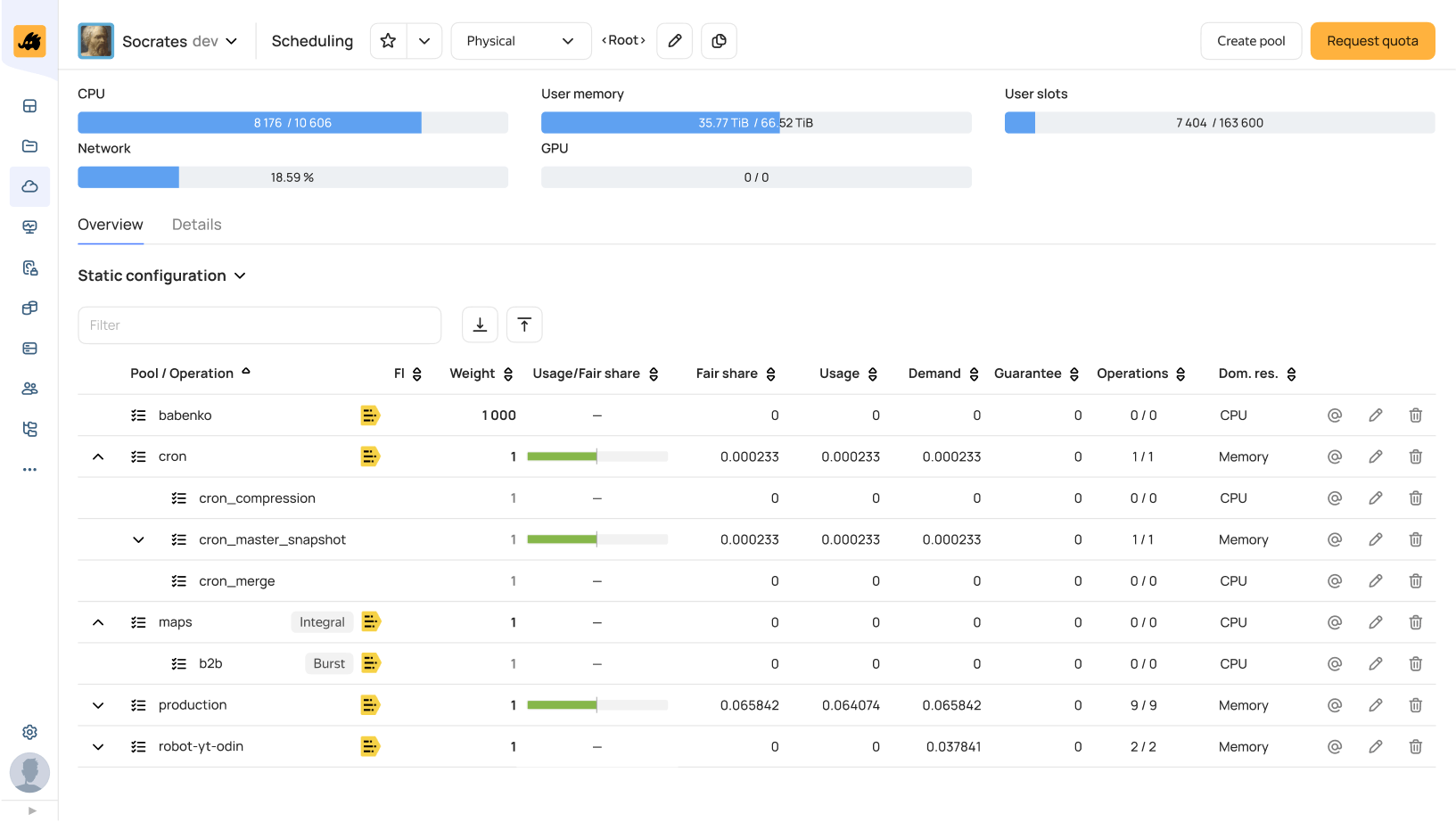

Операции MapReduce можно запускать c помощью YQL — расширенного SQL-подобного языка с UDF, оконными функциями и другими возможностями. С его помощью можно строить сложные процессы обработки данных с сохранением подзапросов в переменные и созданием цепочек зависимых запросов.

Технология, которая позволяет запускать кластера серверов ClickHouse® для работы с данными в YTsaurus. Может работать как источник данных для инструментов визуализации и BI, отлично подходит для ad hoc запросов.

SPYT позволяет запускать кластера Apache Spark в виде операций планировщика, которые могут обрабатывать любые данные из YTsaurus. Удобно для построения ETL-процессов.
Что такое YTsaurus?
Попробовать YTsaurus
